 学习使我快乐
学习使我快乐520不用愁~使用 Node.js 爬取超多情侣头像
声明:本文仅供教学目的,请勿用于违法用途
本篇文章同时收录在公众号《泡芙学前端》
开头
代码量不多哈。520不用愁了,快点选一些可爱的情侣头像送给你的那个TA吧~
步骤:
创建一个 spider 的文件夹
添加依赖:axios、cheerio
根目录下添加 utils 文件夹和 index.js 文件
编写代码
接下来我们先编写 utils 工具函数,用于辅助开发
判断文件夹是否存在
在 utils/isExistDir.js 路径下
js
const fs = require("fs");
const path = require("path");
/**
* 同步
* 判断文件夹是否存在,不存在直接创建
*/
module.exports = function isExitDir(dirName) {
if (!dirName) throw Error("未传入参数");
const absPath = path.resolve(__dirname, `../${dirName}`);
const isExits = fs.existsSync(absPath);
if (!isExits) {
console.log("成功创建根目录", dirName);
fs.mkdirSync(absPath);
}
};睡眠函数
在 utils/sleep.js 路径下,该函数用来做时间等待,防止爬得太快被发现触发限流
js
module.exports = function sleep(ms) {
return new Promise((resolve) => {
setTimeout(resolve, ms);
});
};移除特殊字符函数
在 utils/str.js 路径下,该函数用于去掉文件名的特殊字符(文件名不允许包含特殊字符)
js
module.exports = function excludeSpecial(s) {
s = s.replace(/[\||\“,,\'\"\\\/\b\f\n\r\t]/g, "");
s = s.replace(
/[`~!@#$^&*()=|{}':;',\\\[\]\.<>\/?~!@#¥……&*()——|{}【】';:""'。,、?\s]/g,
""
);
return s;
}主要代码
编写完相关工具函数后我们就开始正式编写代码了
js
const cheerio = require("cheerio");
const axios = require("axios");
const fs = require("fs");
const isExitDir = require("./utils/isExistDir");
const sleep = require("./utils/sleep");
const excludeSpecial = require("./utils/str");
/************
* 爬情侣头像用的脚本
************/
// 执行入口,传入一个时间(单位:ms)控制爬取速度,建议不要太快
getList();
/**
* 获取不同页面的数据,默认获取30页
* @param waitTime 爬取一个页面的间隔时间,默认 2s
*/
async function getList(waitTime = 2000) {
for (let i = 2; i < 30; i++) {
// 爬慢点
await sleep(waitTime * i);
getPage(i);
}
}
// 获取页面内容
async function getPage(num, waitTime) {
let httpUrl = `https://www.woyaogexing.com/touxiang/qinglv/index_${num}.html`;
const res = await axios.get(httpUrl);
const $ = cheerio.load(res.data);
// 首页不需要传入num
httpUrl = httpUrl.replace(`/index_${num}.html`, "");
$(".pMain .txList").each(async (i, element) => {
await sleep(waitTime * i);
const mainTitle = await excludeSpecial($(element).find(".imgTitle").text());
let imgUrl = $(element).find(".img").attr("href");
const currentYear = new Date().getFullYear();
const start = imgUrl.indexOf(`/${currentYear}`);
imgUrl = imgUrl.substring(start, imgUrl.length);
imgUrl = httpUrl + imgUrl;
isExitDir("coupleImg");
fs.mkdir("./coupleImg/" + mainTitle, () => {
console.log("成功创建目录:" + "./coupleImg/" + mainTitle);
});
getImg(imgUrl, mainTitle);
});
}
// 用来获取图片的链接
async function getImg(imgUrl, mainTitle) {
const res = await axios.get(imgUrl);
const $ = cheerio.load(res.data);
$(".contMain .tx-img").each(async (i, element) => {
await sleep(100 * i);
let pageImgUrl = $(element).find("a").attr("href");
pageImgUrl = "http:" + pageImgUrl;
const title = pageImgUrl.substring(39, 71);
download(pageImgUrl, mainTitle, title);
});
}
// 拿到链接之后通过文件流下载
async function download(pageImgUrl, mainTitle, title) {
const res = await axios.get(pageImgUrl, { responseType: "stream" });
const ws = fs.createWriteStream(`./coupleImg/${mainTitle}/${title}.jpg`);
res.data.pipe(ws);
console.log("正在下载" + title);
res.data.on("close", async () => {
console.log("下载完成" + title);
ws.close();
});
}上面就是所有的主要代码了,接下来我们再看看测试效果,在我们项目的根目录中,直接运行 node index.js 即可启动任务
测试效果
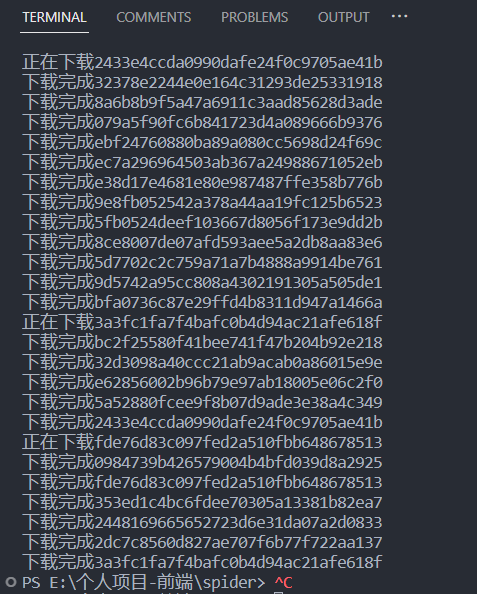
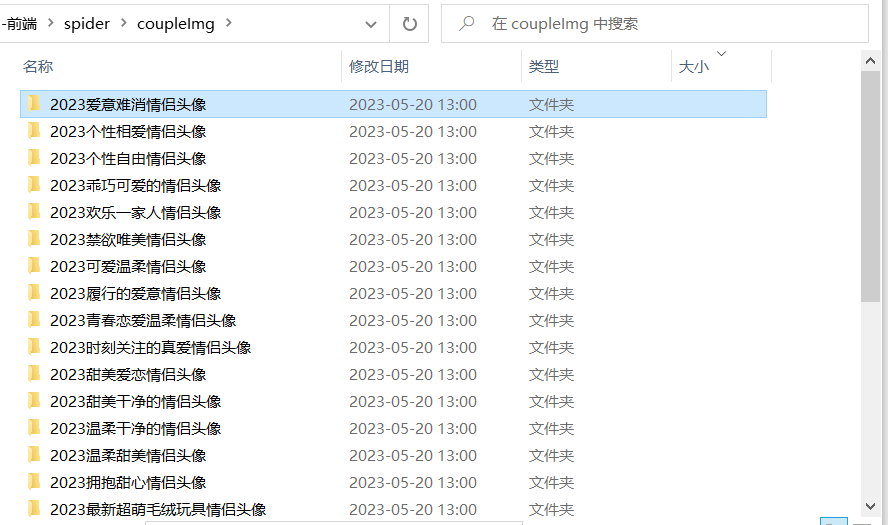
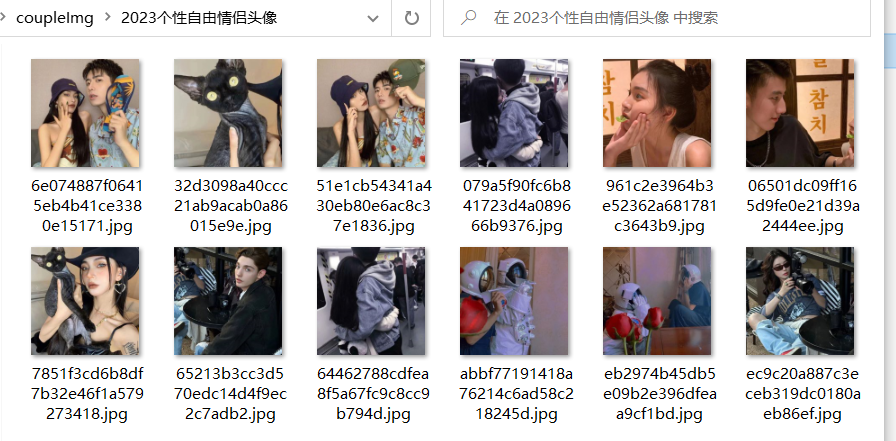
结束
再次声明,仅限学习参考使用哈,不要将人家的网站给爬挂了,不要爬得太快