 学习使我快乐
学习使我快乐简介
众所周知,Rust 是一门性能高、安全性高的原生语言,它拥有和 C++ 相媲美的性能表现,但是却能在编译期帮你杜绝很多隐藏的内存层面的 Bug 。它通过遵循所有权、借用检查、生命周期等规则,一旦代码编译通过,就可以向全世界宣布:老子的代码是内存安全的!这也是为什么说 Rust 更适合做一些底层方面的事情,比如操作系统、数据库、物联网设备、计算领域等。现如今 Rust 已经进入了安卓系统、Windows 系统、Linux 系统中,这三个都是我们日常生活中最常用的系统,还有社区上开源的一个纯 Rust 编写的类 Unix 系统 Redox;而在最近,Vivo 也发布了使用 Rust 编写系统框架的蓝河操作系统。
那么对于我们写应用层的,Rust 有没有用呢? 那当然有。写应用的时候,在适合的地方使用 Rust 也可以获得很不错的性能收益。如果你是前端,可以使用 N-API 来编写 Node.js 原生拓展或者编写 WebAssembly 模块;如果你是写 Python 的,可以使用 Pyo3 来编写原生 Python 拓展模块;如果你是写安卓的,也可以使用 Rust 的所有特性来编写原生操作系统组件(参见);总而言之,Rust 其实已经进入了我们生活的方方面面了,说不定你现在用的设备里的某个软件就包含着 Rust 的代码。
总是在听说 Rust 的性能有多强多强,某某某个框架或者工具用 Rust 重写性能提升了 xx%,本文就抱着一个“纸上得来终觉浅,得知此事要躬行”的心态,去看看其中的一些奥秘。
那么本章我们就以前端领域为切入点,主要讲一下 Rust 在 Node.js 环境下使用 WebAssembly 和 原生拓展之间的一个性能表现,并熟悉一下这两个东西的一个基本开发流程,当我们在前端领域遇到计算场景时,让你可以多一个可以选择的提升方向。
这里先说下我们标题中的结论:
性能: Rust 原生 ≈ NativeAddon > WASM > JavaScript;
测试环境: Windows10、 i7-10875H
斐波那契数列:
| n/耗时 | Rust 原生 | Native Addon | WASM | JS |
|---|---|---|---|---|
| 43 | 0.97s | 1.1s | 2.9s | 3.3s |
| 44 | 1.55s | 1.6s | 4.6s | 5.3s |
| 45 | 2.5s | 2.5s | 7.4s | 8.5s |
快速排序:
包含 100 万个和 1000 万个随机项的数组的对比
| n/耗时 | Rust 原生 | Native Addon | WASM | JS |
|---|---|---|---|---|
| 100_0000 | 0.34s | 0.30s | 0.38s | 0.60s |
| 1000_0000 | 3.63s | 3.10s | 3.55s | 6.70s |
以上测试全部使用 Rust release 模式。
Native Addon 本质上是编译为系统的动态链接库,当 Node.js 的 Native 模块在Linux、 OSX 下编译时,会得到一个带 .node 后缀的 DLL,本质上就是 .dylib,而在 Windows 系统下,.node 本质上就是 .dll。
动态链接库就是会在程序运行时才会把库载入到内存中,然后根据需要再去调用执行库里面的代码。
前置环境
Rust 开发环境
Node.js 开发环境
初始化项目
先创建一个空目录用来初始化开发项目
mkdir rust_in_node
cd rust_in_node初始化 Wasm 模块
编写 Wasm 模块时需要用到工具 wasm-pack,这是 Rust 提供给前端使用的一个一站式 Wasm 解决方案工具,先进行安装:
cargo install wasm-pack接下来使用 wasm-pack 进行项目的初始化:
wasm-pack new wasm_mod初始化 NativeAddon 模块
这里我们需要使用到 @napi-rs/cli ,先需要全局安装:
pnpm install -g @napi-rs/cli然后继续初始化项目,输入:
napi newNativeAddon 是不支持跨平台的,所以需要在每个平台上单独去构建产物,构建生产级 npm 包的时候一般需要把 Linux、MacOS、Windows 系统都选上,然后通过 Github Workflow 来进行发布到 npm 仓库。
这里因为我们要在本地 Windows 系统测试,所以就只选一个 Windows 系统的,并且不开启 Github actions。

初始化 Node.js 测试服务
mkdir server
cd server
pnpm init -y
pnpm i express
touch index.js一会我们要在这里的 index.js 进行测试代码的编写
项目初始化完成之后得到的目录树:
rust_in_node
├── napi_mod
│ ├── Cargo.toml
│ ├── __test__
│ │ └── index.spec.mjs
│ ├── build.rs
│ ├── npm
│ │ └── win32-x64-msvc
│ │ ├── README.md
│ │ └── package.json
│ ├── package.json
│ ├── rustfmt.toml
│ └── src
│ └── lib.rs
├── server
│ ├── index.js
│ ├── package-lock.json
│ ├── package.json
│ └── pnpm-lock.yaml
└── wasm-mod
├── Cargo.lock
├── Cargo.toml
├── README.md
├── src
│ └── lib.rs
└── tests
└── web.rs斐波那契数列测试
我们这里就主要编写 NativeAddon、WASM、JS 的测试代码, Rust 原生的就不展开了,一样的道理。
采用斐波那契的原因是模拟 CPU 密集型场景,使用 Node.js 搭建的服务器的表现情况。
Express 服务
在 server/index.js 文件中,我们提供了 3 个 API,在浏览器上打开对应的端口号就可以看到它们的执行速度
- localhost:3000/js
- localhost:3000/wasm
- localhost:3000/napi
编写如下的测试代码:
const server = require('express')();
const { fib } = require('./wasm_mod');
const { fib: napiFib } = require('./napi_mod');
const getCalcTime = (calcFn, onCalcEnd) => {
const start = performance.now();
const res = calcFn();
const diffTime = ((performance.now() - start) / 1000).toFixed(2);
onCalcEnd(diffTime, res);
};
const TEST_NUM = 43;
function jsFib(n) {
if (n === 0) {
return 0;
}
if (n === 1) {
return 1;
}
return jsFib(n - 1) + jsFib(n - 2);
}
server.get('/wasm', (req, res) => {
getCalcTime(
() => fib(TEST_NUM),
(diffTime, total) => {
const summary = `计算结果为:${total},总耗时:${diffTime}s`;
res.send(summary);
}
);
});
server.get('/js', (req, res) => {
getCalcTime(
() => jsFib(TEST_NUM),
(diffTime, total) => {
const summary = `计算结果为:${total},总耗时:${diffTime}s`;
res.send(summary);
}
);
});
server.get('/napi', (req, res) => {
getCalcTime(
() => napiFib(TEST_NUM),
(diffTime, total) => {
const summary = `计算结果为:${total},总耗时:${diffTime}s`;
res.send(summary);
}
);
});
// 初始化一个路由并绑定3000端口号
server.listen(3000, () => {
console.log('server is running at port 3000');
});WASM 代码
在 wasm-mod/src/lib.rs 文件中,编写如下代码:
use wasm_bindgen::prelude::*;
// 斐波那契数列,时间复杂度 O(2^n)
#[wasm_bindgen]
pub fn fib(n: i32) -> i32 {
match n {
0 => 0,
1 => 1,
_ => fib(n - 1) + fib(n - 2),
}
}然后我们打包编译到 server 目录下,执行命令:
wasm-pack build --out-dir ../server/wasm_mod --target nodejs然后此时在 server 下就能看到一个 wasm_mod 目录
wasm_mod
├── README.md
├── package.json
├── wasm_mod.d.ts
├── wasm_mod.js
├── wasm_mod_bg.wasm
└── wasm_mod_bg.wasm.d.ts一般正常生产环境下,我们都是会把它们发布到 npm 的,但我们这里只是在本地进行测试,所以直接引用这里面的文件就可以了
const { fib } = require('./wasm_mod');NAPI 代码
在 napi-mod/src/lib.rs 文件中,编写如下代码:
#![deny(clippy::all)]
#[macro_use]
extern crate napi_derive;
#[napi]
pub fn fib(n: i32) -> i32 {
match n {
0 => 0,
1 => 1,
_ => fib(n - 1) + fib(n - 2),
}
}然后编译到 server 目录中
napi build ../server/napi_mod --platform --release在 server 目录中,此时我们可以看到多了一个文件夹,里面的 .node 文件就是我们需要的 Node.js NativeAddon,它就是二进制代码,在 Node.js 中执行的时候不会通过虚拟机来运行,而是直接以本机的方式执行,所以性能会比 JS 版本和 WASM 版本的高
napi_mod
├── index.d.ts
├── index.js
└── napi_mod.win32-x64-msvc.node小结
到这里的时候,就可以打开浏览器去访问每一个函数的执行时间了,可以自己尝试着改变 n 的值看看服务的返回结果。
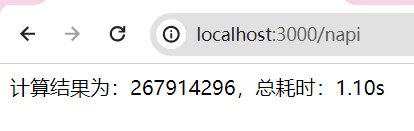
另外这里使用的 Napi 和 Wasm-pack 工具都是用来封装 NPM 包用的,在正常的开发场景,我们一般都会把 NativeAddon 模块和 Wasm 模块单独发布到 NPM 中。
快速排序测试
为什么进行这个测试?
主要是想验证一下超大的数组(对象)在 Rust 和 Js 环境中进行传输的一个性能损耗。
在 Rust 和 Js 环境中进行数据传输时,当我们在 Rust 端使用 Vec 数组接收数据,在 Wasm 环境下 Vec<i32> 默认会转成 Int32Array 类型来进行数据共享,但是在 Napi 环境下,Js 和 Rust 端传输对象或者数组时就会发生数据克隆,数据克隆是非常耗费时间的,如果想要避免克隆,就需要使用 TypedArray 和 Buffer 来进行传输。
TypedArray 是一个描述二进制数据缓冲区的类似数组的东西。使用 TypedArray 可以在 Node.js 和 Rust 之间共享数据,而无需复制或移动底层的数据。可以理解为有一块底层的内存是固定的,然后 Node.js 和 Rust 侧都持有一个执行这块内存的指针来访问它。
Buffer 其实就是 Uint8Array 的子集。
下面我们就来验证一下这个点。
我们这里写一个基础版的快速排序函数(没优化),它的入参是一个打乱的数组。
生成随机数的代码:
function generateRandomArray(length, min, max) {
return Array.from(
{ length },
() => Math.floor(Math.random() * (max - min + 1)) + min
);
}
// 生成包含 1000 万个随机整数的数组
const arrayToSort = generateRandomArray(1000_0000, 1, 1000_0000);JS 版本
function quickSort(arr) {
if (arr.length <= 1) {
return arr;
}
const pivot = arr[0];
const left = [];
const right = [];
for (let i = 1; i < arr.length; i++) {
if (arr[i] < pivot) {
left.push(arr[i]);
} else {
right.push(arr[i]);
}
}
return quickSort(left).concat(pivot, quickSort(right));
}Rust 版本
fn quick_sort(mut arr: Vec<i32>) -> Vec<i32> {
if arr.len() <= 1 {
return arr;
}
let pivot = arr.remove(0);
let (mut left, mut right): (Vec<i32>, Vec<i32>) = arr.into_iter().partition(|&x| x < pivot);
left = quick_sort(left);
right = quick_sort(right);
left.push(pivot);
left.extend(right);
left
}然后我们继续按照上面斐波那契数列的思路来将 Rust 版本的代码编译到 Wasm 和 Napi 中。
编译为 Wasm 后,我们可以看到可以直接获得这样的一个 TS 类型,Int32Array 就是上面提到的 TypedArray
export function quick_sort(arr: Int32Array): Int32Array;而 Rust 转 Native Addon 时,会生成普通的数组类型
export function quick_sort(arr: Array<number>): Array<number>;这样的话数据的传输成本就会非常的高,因为内部在传输数据的过程中发生了深克隆。接下来让我们来验证一下这一点:
上面的 Rust 版本编译到 Native Addon 之后,排序 1000 万数据的乱序数组,耗时一共 5.10 s 左右。而 WASM 版本耗时在 3.5 s 左右,这差异还是挺大的。
那么优化的思路就是使用 TypeArray 使用共享内存去避免传输数据的深克隆。
我们将 napi 代码改成这样子,把类型从 Vec<i32> 改成了 Int32Array
#[napi]
pub fn quick_sort(arr: Int32Array) -> Int32Array {
let arr: Vec<i32> = arr.to_vec();
let result = inner_quick_sort(arr);
Int32Array::new(result)
}
fn inner_quick_sort(mut arr: Vec<i32>) -> Vec<i32> {
if arr.len() <= 1 {
return arr;
}
let pivot = arr.remove(0);
let (mut left, mut right): (Vec<i32>, Vec<i32>) = arr.into_iter().partition(|&x| x < pivot);
left = inner_quick_sort(left);
right = inner_quick_sort(right);
left.push(pivot);
left.extend(right);
left
}对应的 JS 侧代码也要做修改
server.get('/quickSortNapi', (req, res) => {
const arr = new Int32Array(arrayToSort);
getCalcTime(
() => quickSortNapi(arr),
(diffTime, total) => {
const summary = `总耗时:${diffTime}s`;
res.send(summary);
}
);
});然后此时我们再编译来运行看看,最后降到了 3.1 s,比 WASM 版本的要快一些了
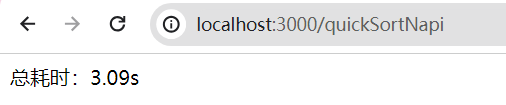
然后我们再来验证一下是不是真的没发生克隆,我们将 Rust 侧的代码修改一下,将返回结果的第一项改成 11111
#[napi]
pub fn quick_sort(arr: Int32Array) -> Int32Array {
let arr: Vec<i32> = arr.to_vec();
let mut result = inner_quick_sort(arr);
result[0] = 11111;
Int32Array::new(result)
}然后在 JS 侧打印一下这个结果
server.get('/quickSortNapi', (req, res) => {
const arr = new Int32Array(arrayToSort);
getCalcTime(
() => {
const data = quickSortNapi(arr);
console.log('data', data);
},
(diffTime, total) => {
const summary = `总耗时:${diffTime}s`;
res.send(summary);
}
);
});可以看到确实如此
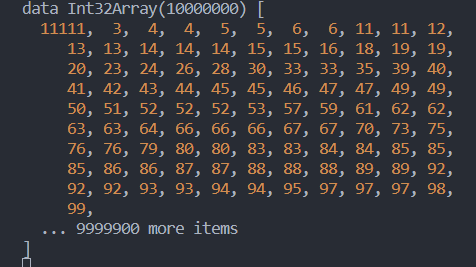
这一点官方文档其实也是提到了的。就是要想办法避免发生数据移动/数据克隆这样的耗时行为来提高程序的性能。
数组的话使用 TypeArray 即可,那么如果是超大的对象需要在 Rust 和 Node.js 之间进行传输,可以在 JS 侧将对象转成字符串再通过 Buffer 来和 Rust 进行通信,这样虽然也有一点点性能损耗,但是也会比直接传输一个大对象的性能远远要高,在 SWC 的源码里它就是这么干的。
总结
以上的一些就是我最近在学习 Rust 过程中探索到的一些东西,其中为了了解 Rust 是如何给 Node.js 提高性能的,我去翻看了 SWC 的源码(这货刚出来那会一直在吹比 Babel 提升了好几十倍的性能),带着这个问题去寻找答案,然后了解到了一些神奇的数据传输的用法,也就是上面提到的几个点,虽然官方文档也提了一嘴,但是描述的非常非常简单。
在 SWC 的内部会优先使用 Native Addon 来进行代码的编译,而当环境不支持 Native Addon 的时候就会走 WASM 来进行兜底(V8 引擎内置的 WASM 运行时)。
另外 Native Addon 其实开发起来还是稍微有点麻烦的,因为不支持跨平台,需要在发包的时候云端编译到多平台上再发布,而 WASM 的开发就简单很多了,它在服务端侧的最大受益点就是可以跨平台,编译出的一份代码在任何系统都可以运行,但是毕竟它还是运行在堆栈虚拟机中的,性能会没原生那么好,但是很多时候它其实也是个不错的选择,比如想要把代码也复用到浏览器上的时候。不管怎样,这两个场景 Rust 都能 Cover 掉就是了。