 学习使我快乐
学习使我快乐来来来,我们继续先前 Rust 文章系列的学习,没看过之前文章的可以点进主页看看。
什么是字符串和切片
首先我们得知道字符串是个什么玩意儿。在别的语言中字符串的使用比较简单,但是在 Rust 中字符串会稍微复杂些,本篇文章中,我们主要需要弄明白的就是字符串和切片。
- 字符串是由字符组成的连续集合,它是 UTF-8 编码,其所占的字节数是变化的(1到4个),在 Rust 中它的表示类型是
String。String类型是可变的、拥有所有权的字符串。它在堆上存储字符串数据,长度是动态可变的。当你需要修改字符串内容、动态拼接字符串或者从其他数据类型转换成字符串时,通常会使用String类型。 - 切片可以引用集合中某些连续的部分,比如字符串就是一个集合,切片可以表示一部分的字符串引用,在 Rust 中它的表示类型是
&str。引用字符串的时候使用[开始索引..结束索引]这样的语法。比如 [0..2],就会获取第一第二个字符,也可以缩写为 [..2],如果要取第三个字符到最后一个可以写 [3..]。&str类型是不可变的字符串切片,它不拥有字符串数据,而是指向内存中的某个字符串片段。&str类型通常通过字符串字面量创建,也可以通过String类型的as_str方法获得。&str类型主要用于函数参数、字符串切片和字符串的查询等场景。
下面我们看个例子:
fn main() {
// 写代码的时候类型可以不显式声明,编译器会推断
let s: String = String::from("Hello World");
// 对字符串的引用就是切片类型
let hello: &str = &s[0..5];
let world: &str = &s[6..11];
println!("{}", hello); // Hello
println!("{}", world); // World
// 直接声明 &str 切片
let s: &str = "Hello World";
}字符串的基本实现原理
Rust 的字符串类型是基于 UTF-8 编码的,这意味着它支持任意 Unicode 字符。在内存中,字符串被存储为连续的字节序列,每个字符可能占用不同数量的字节。UTF-8 编码保证了字符串的灵活性和兼容性。
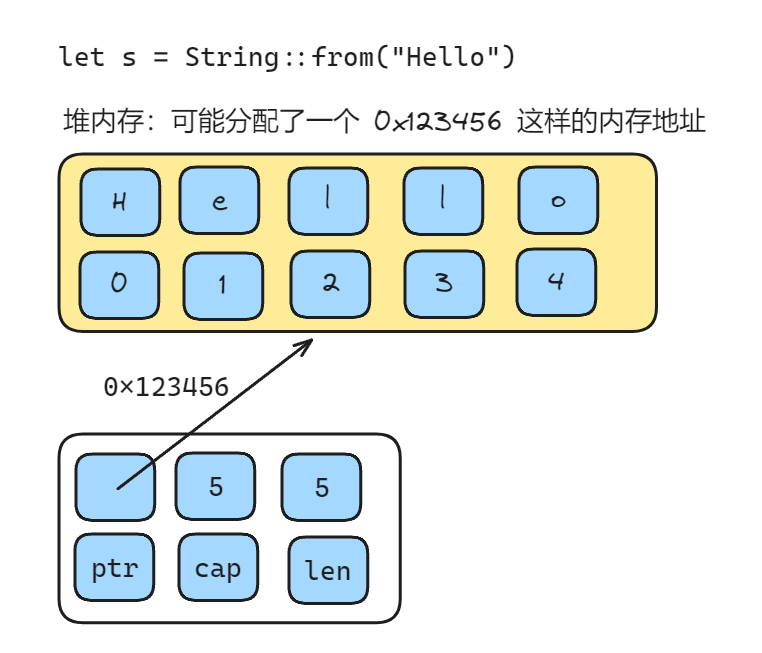
对于 String 类型,它在堆上分配一块内存用于存储字符串数据,并维护一个指向堆上字符串数据的指针、长度和容量等元数据信息。当需要修改字符串时,String 类型会动态调整内存空间的大小,以容纳新的字符数据。
接下来我们看下标准库中 String 的实现
#[derive(PartialEq, PartialOrd, Eq, Ord)]
pub struct String {
vec: Vec<u8>,
}从上面的代码中我们可以看到,它的内部就由 Vec 构成的,所以它就是一个 u8 类型的集合,大部分 Vec 拥有的方法它也拥有,包括动态扩容的逻辑也是一样的。同时还有一些它自己相关的方法,比如用来处理 utf8 的 from_utf8 和 from_utf8_lossy 等方法。
而我们上面说到 String 会维护堆上的字符串指针、长度和容量,我们继续看下 Vec 的实现,下面是简化版的标准库中的代码
pub struct Vec<T> {
buf: RawVec<T>,
// 长度
len: usize,
}
pub struct RawVec<T> {
// 指向堆上的指针,它是一个编译时长度不确定的指针
ptr: Unique<T>,
// 容量
cap: Cap,
}而对于 &str 类型,它只是一个指向字符串内存片段的引用,通常包括起始地址和长度信息。由于 &str 类型是不可变的,它无法修改字符串数据,只能访问和查询其中的内容。
字符串在内存中的分布
字符串之间的相互转换
下面介绍了一些常用相关字符串和别的类型的互相转换的方法
| from | to | 方法 |
|---|---|---|
| &str | String | String::from(s) 或 s.to_string() 或 s.to_owned() |
| &str | &[u8] | s.as_bytes() |
| &str | Vec | s.as_bytes().to_vec() |
| String | &[u8] | s.as_bytes() |
| String | &str | s.as_str() 或 &s |
| String | Vec | s.into_bytes() |
| &[u8] | &str | std::str::from_utf8(s).unwrap() |
| &[u8] | Vec | s.to_vec() |
| Vec | &str | std::str::from_utf8(&s).unwrap() |
| Vec | String | String::from_utf8(s).unwrap() |
| Vec | &[u8] | &s 或 s.as_slice() |
常用字符串 API
下面我们来看下 Rust 字符串会有哪些常用的方法,以及它和对应的 JavaScript 版本的对比实现:
新建字符串
Rust:
rust// 三个方法都行 let s = String::from("hello"); let s = "hello".to_string(); let s = "hello".to_owned();JavaScript:
javascriptconst s = "hello";追加字符串
Rust:
rustlet mut s = String::from("hello"); s.push_str(", world!");或者直接使用加号, String 实现了 AddAssign 这个 trait, 对加号进行了运算符重载
s += ",world!";rustimpl AddAssign<&str> for String { fn add_assign(&mut self, *other*: &str) { self.push_str(*other*); } }JavaScript:
javascriptlet s = "hello"; s += ", world!";遍历字符串
Rust:
rustfor c in "hello".chars() { println!("{}", c); }JavaScript:
javascriptfor (let c of "hello") { console.log(c); }字符串转换为切片
Rust:
rustlet s = String::from("hello"); // let slice: &str = s.as_str(); let slice: &str = &s[0..1];JavaScript:
javascriptconst s = "hello"; const slice = s.slice(0, 1); // 类似吧字符串替换
Rust:
rustlet s = String::from("hello"); let replaced = s.replace("l", "L");JavaScript:
javascriptconst s = "hello"; const replaced = s.replace("l", "L");大小写转换
Rust:
rustlet s = String::from("hello"); let uppercased = s.to_uppercase(); let lowercased = s.s.to_lowercase();JavaScript:
javascriptconst s = "hello"; const uppercased = s.toUpperCase(); const lowercased = s.toLowercase();移除空格
Rust:
rustlet s = String::from(" hello "); let trimmed = s.trim();JavaScript:
javascriptconst s = " hello "; const trimmed = s.trim();另外两个语言都有移除开头和移除末尾空格的方法 trim_start、trim_end。
获取字符串长度
Rust:
rustlet s = String::from("hello"); let length = s.len();JavaScript:
javascriptconst s = "hello"; const length = s.length;字符串中是否包含某些字符串
Rust:
rustlet s = String::from("hello"); let contains = s.contains("ell");JavaScript:
javascriptconst s = "hello"; const contains = s.includes("ell");分割
Rust:
rustlet s = String::from("hello,world"); let parts: Vec<&str> = s.split(",").collect(); // 还有 split_whitespace()JavaScript:
javascriptconst s = "hello,world"; const parts = s.split(","); // JS 的split(" ") 对应 Rust 的 split_whitespace()
另外还有非常多的方法,等到用的时候可以自行去查阅相关文档或看标准库,这里也只是抛砖引玉一下。
使用时需要注意的点
当我们遍历 utf8 字符串的时候,稍微注意一下,比如要以 Unicode 字符去遍历中文,需要使用到 chars 方法,因为大部分中文在 utf8 编码中的长度是 3个字节。
比如:
fn main() {
let s = String::from("我叫泡芙");
// 如果切片是 [0..1] 就会报错
// 打印:我
println!("{:?}", &s[0..3]);
// 如果需要遍历中文就需要使用 chars 方法
// 分别打印: 我 是 泡 芙
for c in s.chars() {
println!("{}", c);
}
}总结
这篇文章我们对 Rust 的字符串有了一个初步的了解,对于 &str 类型来说,它最终是直接以硬编码的形式放到最终可执行文件内的,因为它的大小是已知并且不可变的,在编译时我们就明确知道了它的所有信息,所以它的性能会更高。而对于 String 类型来说,因为它是可变的,所以它的大小在编译时未知,只能把它放到堆上,后续的操作都在运行时去完成。
今天的学习差不多先到这里吧~ 祝大家在学习 Rust 的路上越挫越勇。